Apple M3 Machine Learning Speed Test
I put my M1 Pro against Apple's new M3, M3 Pro, M3 Max, a NVIDIA GPU and Google Colab.


I've been using my M1 Pro MacBook Pro 14-inch for the past two years.
I bought the upgraded version with extra RAM, GPU cores and storage to future proof it.
And it hasn't missed a beat.
But Apple's latest release of the M3 series got me curious.
I watched the presentation and saw a bunch of graphs about it being their biggest GPU performance leap in years.
Being a machine learning engineer, naturally, this got me curious about how they would perform from a machine learning standpoint.
My M1 Pro is unmatched in day-to-day usage.
I love it.
But I wouldn't go training larger scale machine learning models on it.
Can the M3 series change this?
I did a bunch of tests to find out.
Resources
- Code on GitHub – all of the code I used to setup and run the tests across the machines can be found on GitHub.
- Video walkthrough – I also made a video walkthrough of all the results plus a few tips and recommendations on YouTube.
Machines we're testing
The following are the machines I tested.
For all of the M3 variants of the MacBook Pro, they were the base model in their class (e.g. an M3 Pro MacBook Pro with no upgrades from the Apple Store).
| Machine | CPU | GPU | RAM | Storage | Price (USD) |
|---|---|---|---|---|---|
| M1 Pro 14" 2021 | 10-core CPU | 16-core GPU | 32GB | 4TB SSD | ~$3,500 |
| M3 14" 2023 | 8-core CPU | 10-core GPU | 8GB | 512GB SSD | $1,599 |
| M3 Pro 14" 2023 | 11-core CPU | 14-core GPU | 18GB | 512GB SSD | $1,999 |
| M3 Max 14" 2023 | 14-core CPU | 30-core GPU | 36GB | 1TB SSD | $3,199 |
| Deep Learning PC | Intel i9 | NVIDIA TITAN RTX (24GB) | 32GB | 1TB SSD | ~$3,000 |
| Google Colab Free Tier | 2-core CPU | NVIDIA Tesla V100 (16GB) | 12GB | 100GB SSD | Free or $10/month for more compute |
Tests we're performing
You can find all of the code for the following tests on GitHub.
| Experiment | Model | Dataset | Num Samples | Problem Type | Backend |
|---|---|---|---|---|---|
| 1 | ResNet50 (CNN) | CIFAR100 | 50,000 train, 10,000 test | Image Classification | PyTorch |
| 2 | ResNet50 | Food101 | 75,750 train, 25,250 test | Image Classification | PyTorch |
| 3 | DistilBERT (Transformer) | IMDB | 25,000 train, 25,000 test | Text Classification | PyTorch |
| 4 | ResNet50 | CIFAR100 | 50,000 train, 10,000 test | Image Classification | TensorFlow |
| 5 | ResNet50 | Food101 | 75,750 train, 25,250 test | Image Classification | TensorFlow |
| 6 | SmallTransformer | IMDB | 25,000 train, 25,000 test | Text Classification | TensorFlow |
| 7 | Llama 2 7B Q4_0.gguf | N/A | 100 (generate 100 answers) | Text Generation | llama.cpp |
| 8 (bonus) | Geekbench ML | Multiple | Multiple | Multiple | Core ML |
Notes:
- Only training time was measured as this generally takes far more time than inference (except for Llama 2 text generation and Geekbench ML, these were inference only).
- If a result isn't present for a particular machine (in the graphs below), it means it either failed or didn't have enough memory to complete the test (e.g. M3 Pro 14" 2023 with 8GB RAM couldn't run batch size 64 for PyTorch CV Food101).
- All training was done in float32, as because as far as I know, mixed precision training isn't available on M-series chips with PyTorch/TensorFlow. This means that if it was, training times would likely be almost halved.
- All experiments focus on measuring speed only and not accuracy/performance.
Results
Each of the following results were recorded in December 2023.
So they may change as frameworks update and can leverage hardware better.
Major versions:
- PyTorch 2.1.0, TorchVision 0.16.0
- TensorFlow 2.15.0
- Transformers 4.35.2
Full results can be viewed in the results/ directory on GitHub.
1 - PyTorch Computer Vision (CIFAR100)
| Model | Dataset | Image Size | Epochs | Num Samples | Num Classes | Problem Type |
|---|---|---|---|---|---|---|
| ResNet50 | CIFAR100 | 32x32x3 | 5 | 50,000 train, 10,000 test | 100 | Image Classification |
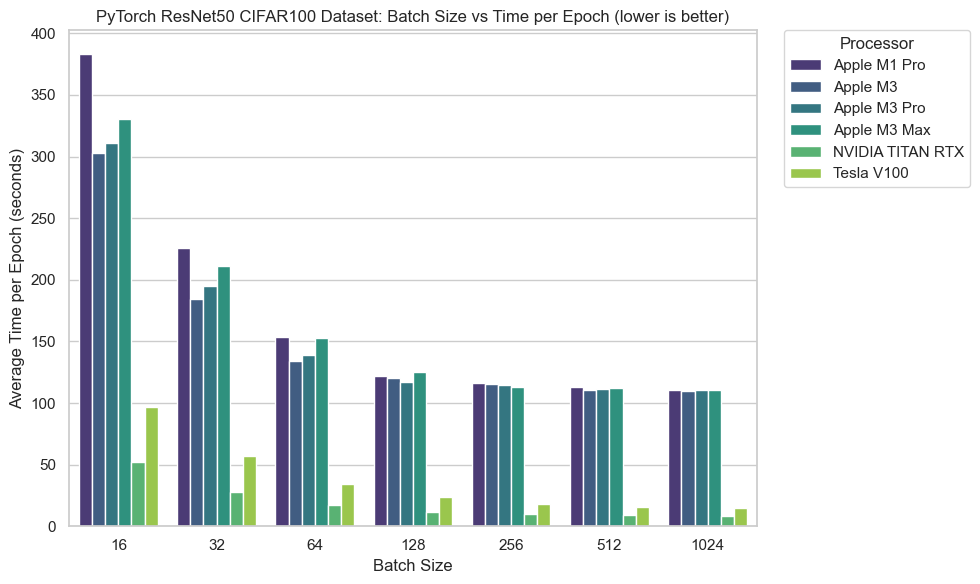
A trend across almost all experiments (and in practical ML setups) is that you generally get faster performance the more you pack the GPU.
In essence, with a lower batch size and a small dataset (CIFAR100 is only 32x32 images), much of the time is spent moving data around rather than computing on it.
From Figure 1 we can see that as the batch size increases, the average time per epoch goes down (until it saturates at 256 and above).
And then many of the M-series chips level out in terms of time per epoch. This is strange as I thought there would've been more of a difference across different numbers of GPU cores/age of the chips.
The NVIDIA chips have the best performance by a long shot across all batch sizes.
2 - PyTorch Computer Vision (Food101)
| Model | Dataset | Image Size | Epochs | Num Samples | Num Classes | Problem Type |
|---|---|---|---|---|---|---|
| ResNet50 | Food101 | 224x224x3 | 5 | 75,750 train, 25,250 test | 101 | Image Classification |
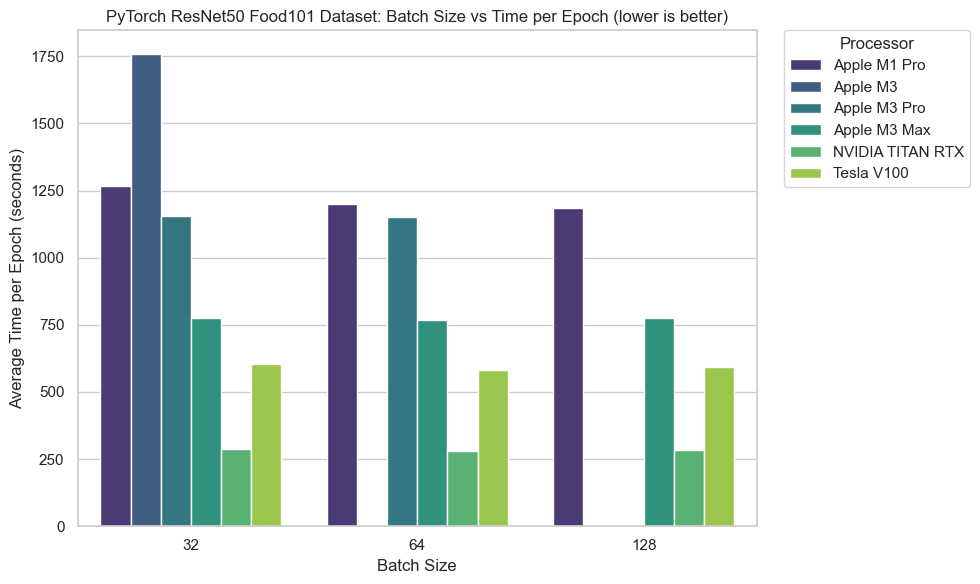
The numbers get closer on a larger dataset.
Food101 image tensors (224x224x3) have ~49x more elements in them than CIFAR100 image tensors (32x32x3).
224x224x3 is also the current image size I use to train the computer vision models that power Nutrify (an app my brother I have built to help people learn about food).
So the Food101 dataset with 100,000+ images is closer to a real world experiment.
It’s clear when filling up the GPUs with data, the speed gap narrows between the M3 Max (30 core GPU) and the NVIDIA GPUs.
A larger dataset is also where we see the RAM of the M3 (8GB) and M3 Pro (18GB) maxing out (out of memory) with larger batch sizes.
3 - PyTorch Natural Language Processing (NLP)
| Model | Dataset | Sequence Size | Epochs | Num Samples | Num Classes | Problem Type |
|---|---|---|---|---|---|---|
| DistilBERT (fine-tune top 2 layers + top Transformer block) | IMDB | 512 | 5 | 25,000 train, 25,000 test | 2 | Text Classification |
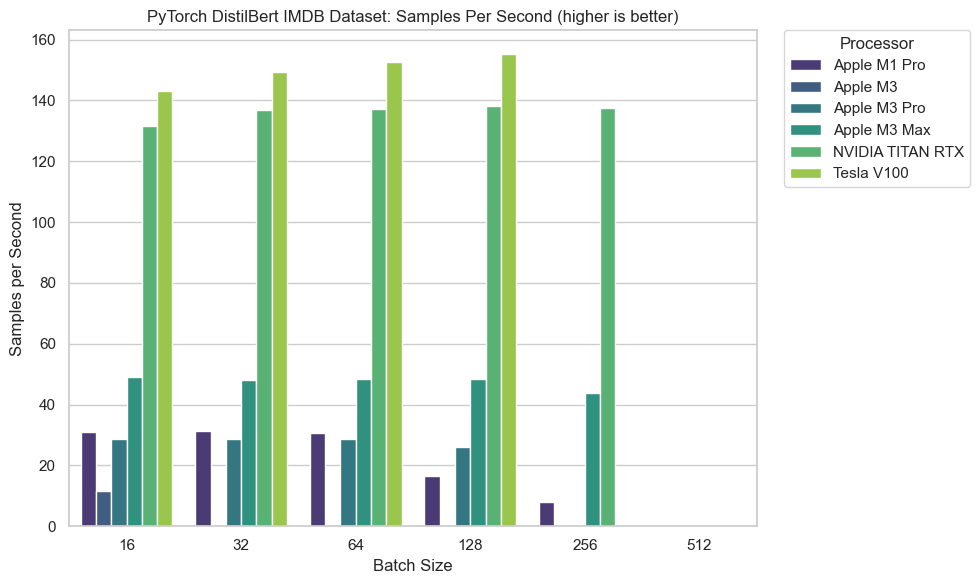
DistilBERT is a modern NLP neural network.
And fine-tuning the last few layers of a network for a specific task is a very common workflow.
This test measured samples per second where higher is better.
The results show here that more GPU cores is better.
With results following closely to the number of cores for the M-series chips.
Notably, my two-year-old M1 Pro outperformed the brand new M3 Pro.
This is likely due to my M1 Pro having 2 more GPU cores than M3 Pro (16 vs 14).
Though no M-series chip was close to the performance of the NVIDIA chips.
Finally, it’s clear that when training larger models like DistilBERT, memory (RAM or VRAM), as the M3 failed to complete an epoch with a batch size of 32 or above (out of memory).
For the highest batch sizes, only the machines with the largest amount of RAM were about to complete them. So if you want to train or use larger models, it's clear you'll want more RAM.
4 - TensorFlow Computer Vision (CIFAR100)
| Model | Dataset | Image Size | Epochs | Num Samples | Num Classes | Problem Type |
|---|---|---|---|---|---|---|
| ResNet50 | CIFAR100 | 32x32x3 | 5 | 50,000 train, 10,000 test | 100 | Image Classification |
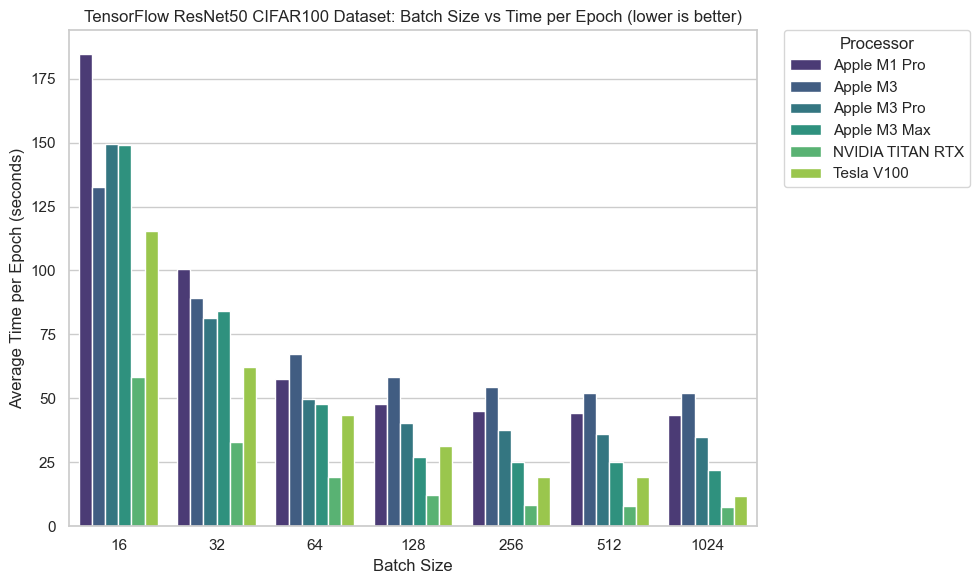
We see the same trend again with the TensorFlow backend on CIFAR100.
Average time per epoch is greater with lower batch sizes.
Again, likely because with such small batch sizes and data samples the majority of time is spent moving data around than actually computing on it.
Time per epoch steadily decreases as batch size increases.
And we see an increasing performance with more GPU cores across the M-series.
Notably again, the M1 Pro keeps the pace with the M3 Pro and outperforms the M3 across almost every batch size.
5 - TensorFlow Computer Vision (Food101)
| Model | Dataset | Image Size | Epochs | Num Samples | Num Classes | Problem Type |
|---|---|---|---|---|---|---|
| ResNet50 | Food101 | 224x224x3 | 5 | 75,750 train, 25,250 test | 101 | Image Classification |
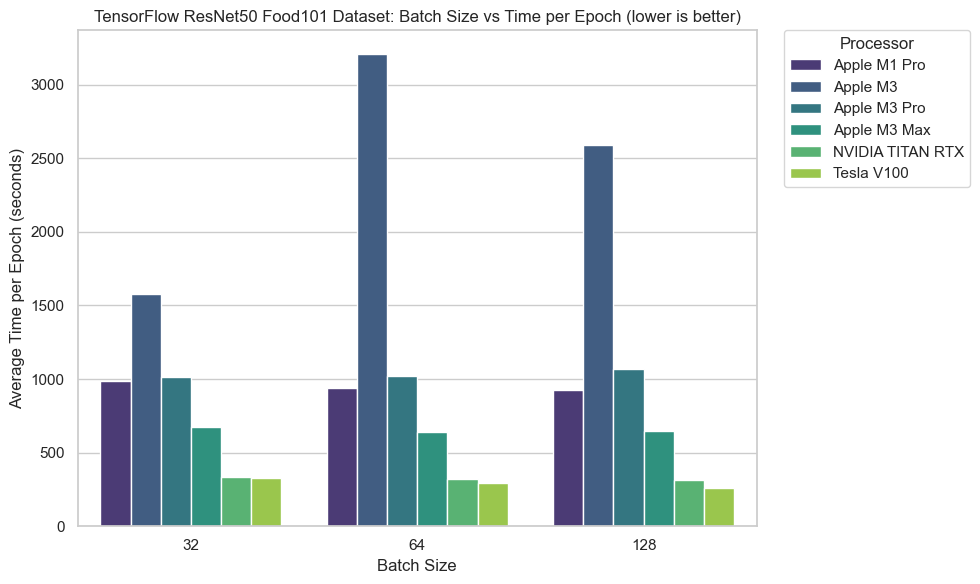
This experiment saw some of the closest results across the board.
With exception for the M3, most machines were within 100% performance of each other.
The M1 Pro with 16 GPUs also outperformed the M3 (10 core GPU) and M3 Pro (14 core GPU) across all batch sizes.
The M3 Max (30 core GPU) also closed the gap between the NVIDIA cards.
However, both NVIDIA cards shined when utilising all available cores and memory thanks to the larger data size.
6 - TensorFlow Natural Language Processing (NLP)
| Model | Dataset | Sequence Size | Epochs | Num Samples | Num Classes | Problem Type |
|---|---|---|---|---|---|---|
| SmallTransformer (custom) | IMDB | 200 | 5 | 25,000 train, 25,000 test | 2 | Text Classification |
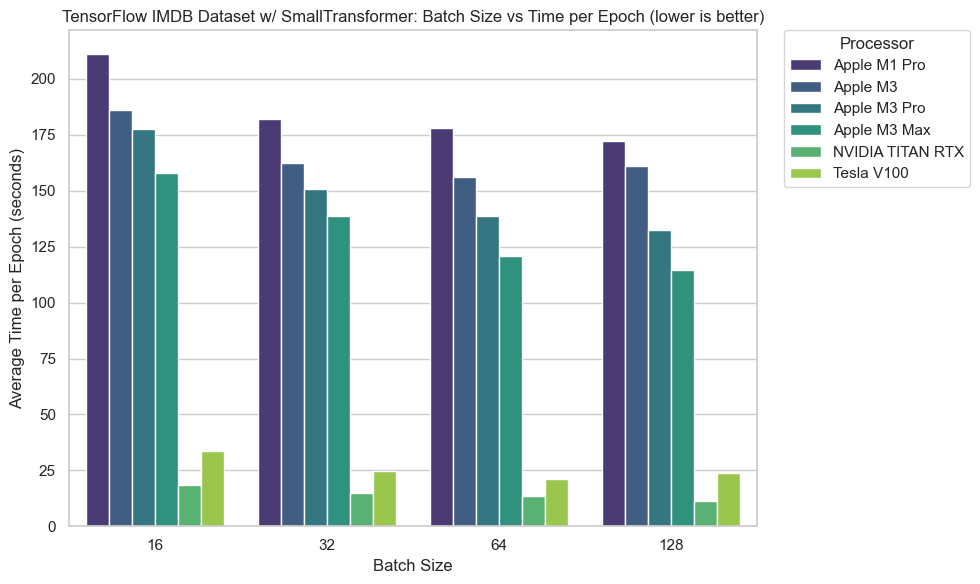
For this experiment I coded up my own SmallTransformer model (a neural network with a single transformer block).
Figure 6 shows one of the clearest trends amongst the experiments.
M-series chips performed better as they got newer and larger in terms of GPU cores (M3 Max > M3 Pro > M3 > M1 Pro).
And once again, the NVIDIA chips performed far better than the rest of the machines, sometimes 8-9x better.
7 - Llama 2 7B Text Generation
| Model | Task | Num Questions | Num Answers | Total Generations | Backend |
|---|---|---|---|---|---|
| Llama 2 7B .gguf format | Text Generation | 20 | 5 | 20*5 = 100 | llama-cpp-python |

.gguf format across 100 generation tasks (20 questions, 5 times each) using llama-cpp-python backend.With new formats like .gguf, LLMs are getting easier and easier to use on device.
And it’s not inconceivable that within the next 12 months (I’m writing this in December 2023) we’ll see ChatGPT-level performance from models running purely on device, no internet connection required.
One of the main metrics to measure for current LLMs is tokens generated per second (as in, how many words per second can the model output when you ask it a question).
In this case, higher is better.
And here the trend was again, more GPU cores means higher performance.
The M1 Pro outperformed the M3 and M3 Pro but the M3 Max with 30 GPU cores pulled out in front.
However, something to note is that for me, anything over 25-30 tokens per second is above reading speed.
So of course whilst metrics of higher tokens per second would be better, it’s important to note that 35 tokens per second (M1 Pro) and ~48 tokens per second (M3 Max) is definitely more than usable from a practical standpoint.
8 - Geekbench ML
I've seen Geekbench scores for various chips over the years.
But this is the first time I've tried Geekbench ML.
So I was excited to see the outcomes.
All tests were done using Geekbench ML 0.6.0 for Mac.
Tests include a series of inference-only benchmarks across different domains.
All machines have a 16-core Neural Engine.
| Machine | Num CPU cores | CPU | CPU-link | Num GPU Cores | GPU | GPU-link | Neural Engine | Neural Engine-link |
|---|---|---|---|---|---|---|---|---|
| MacBook Pro M1 Pro 14 inch, 2021 | 10 | 1809 | Link | 16 | 5192 | Link | 6462 | Link |
| MacBook Pro M3 14 inch, 2023 | 8 | 2356 | Link | 10 | 5747 | Link | 8399 | Link |
| MacBook Pro M3 Pro 14 inch, 2023 | 11 | 2355 | Link | 14 | 7030 | Link | 10237 | Link |
| MacBook Pro M3 Max 14 inch, 2023 | 14 | 2393 | Link | 30 | 9008 | Link | 9450 | Link |
Notably, the M3 outperforms the M1 Pro in the Geekbench ML scores, however, in practice, it seems the M1 Pro can perform on par or even outperform the M3.
As for the neural engine, I'm not 100% sure why the M3 Pro performs the best in comparison to the M3 Max. I tested these two several times and recorded the highest score for each.
I guess in practice, you won't notice this difference though.
As far as I know, the neural engine kicks in for inference tasks and there is still a bit of black magic behind how and when it actually works.
Discussion
It's quite clear that the newest M3 Macs are quite capable of machine learning tasks.
However, dedicated NVIDIA GPUs still have a clear lead.
The results also show that more GPU cores and more RAM equates to better performance (e.g. M3 Max outperforming most other Macs on most batch sizes).
An interesting result was that the M3 base chip outperformed (or performed level with) the M3 Pro and M3 Max on smaller-scale experiments (CIFAR100, smaller batch sizes).
I'm not 100% sure why this is the case but my intuition tells me this is likely because the overhead of copying data to and from the GPU is more expensive than the actual training itself (e.g. the GPU is waiting for data to be copied to it, rather than being fully utilised).
So in practice, the M3 can compete with M3 Pro and M3 Max because the actual computation doesn't take long but the copying does.
Either way, the Food101 examples show a more realistic example with larger image sizes. It's here that the machines with more GPU cores perform faster and the machines with more RAM can handle larger batch sizes.
For the best results, you'll want to always pack as much data into the GPU as possible (to use all of your GPU cores) and avoid copying data between memory.
I thought that the unified memory system on the M-series chips would reduce copying overheads. Perhaps this is not yet the case from a software perspective (e.g. PyTorch and TensorFlow are not designed for Apple Silicon).
Maybe newer frameworks designed for Apple Silicon such as MLX will better utilise the unified memory system. This will require further investigation.
I was also very impressed by the performance of the M1 Pro I bought 2 years ago (with upgrades). It was able to outperform the base M3 and could keep up with or perform better than the M3 Pro on almost all benchmarks.
It seems Apple may have gone too hard on the M1 chips, as they are still performing outstandingly well two years later.
Finally, all experiments were conducted in float32. And as far as I know, float16 (half-precision) training isn't yet possible on the M-series chips with TensorFlow/PyTorch. Training in float16 would definitely see the NVIDIA GPUs pull even further ahead (and subsequently I'd assume the same for Apple Silicon Macs once it becomes available).
The Geekbench ML results were as expected (newer and bigger chips doing better) with the exception of the M3 Max performing slightly worse on the Neural Engine than the M3 Pro. However, I'd take this number with a grain of salt as it will likely be close to unnoticed in real-world applications.
Recommendations
For smaller experiments, fine-tuning models and learning the fundamentals of machine learning, the M3 Macs will be more than fine to use.
But for larger scale workloads, you'll likely still want a dedicated NVIDIA GPU.
Personally, I use my M1 MacBook Pro as a daily driver but perform all larger-scale deep learning experiments on my NVIDIA GPU PC (connected via SSH).
For example, I do plenty of data exploration for Nutrify but all model training happens on a NVIDIA TITAN RTX.
And Google Colab helps to fill in the gaps whenever necessary.
Based on the results across the new M3 Macs, I'm not going to upgrade my M1 MacBook Pro.
But I am curious to see how a spec'd up M3 Max (or future M3 Ultra) would go with a dedicated MLX model against my NVIDIA GPU PC.
In summary my recommendations are:
- Go for as much RAM and GPU cores as you can afford, typically in that order.
- More GPU cores = faster training/inference.
- More RAM = larger batch sizes/models.
- Avoid the 8GB RAM M3, 16GB is a good minimum.
- As value for money, the M3 Pro with a RAM upgrade (16GB -> 36GB) and GPU upgrade (14-cores -> 18 cores) still comes in cheaper than an M3 Max.
- If you've got the option, perhaps spend less on a MacBook and buy a dedicated NVIDIA GPU and setup a deep learning PC you can SSH into (this is what I do).
- For example, get the baseline M3 with a RAM upgrade and spend the rest of the money on a NVIDIA GPU.
See the GitHub for more notes on the experiments and the video walkthrough for a more visual overview.