CS329s Machine Learning Deployment Tutorial
If you're smart enough to build machine learning models, you're smart enough to deploy them.


I started learning machine learning through Stanford lectures and tutorials in 2017. Last week, I gave one of my own.
Chip Huyen (the course coordinator + lead instructor) reached out after seeing my YouTube video on machine learning deployment and asked if I’d like to give a tutorial to Stanford CS329s (Machine Learning Systems Design) students doing something similar and of course I said yes.
It’ll be live, is that okay? She asked.
Sure. A live demo of deploying a machine learning model across six time zones (I live in Brisbane, Australia, Stanford is in California), what could go wrong?
Despite my practice on a few Twitch livestreams, I went overboard on time but I think I got across the main points I was trying to convey.
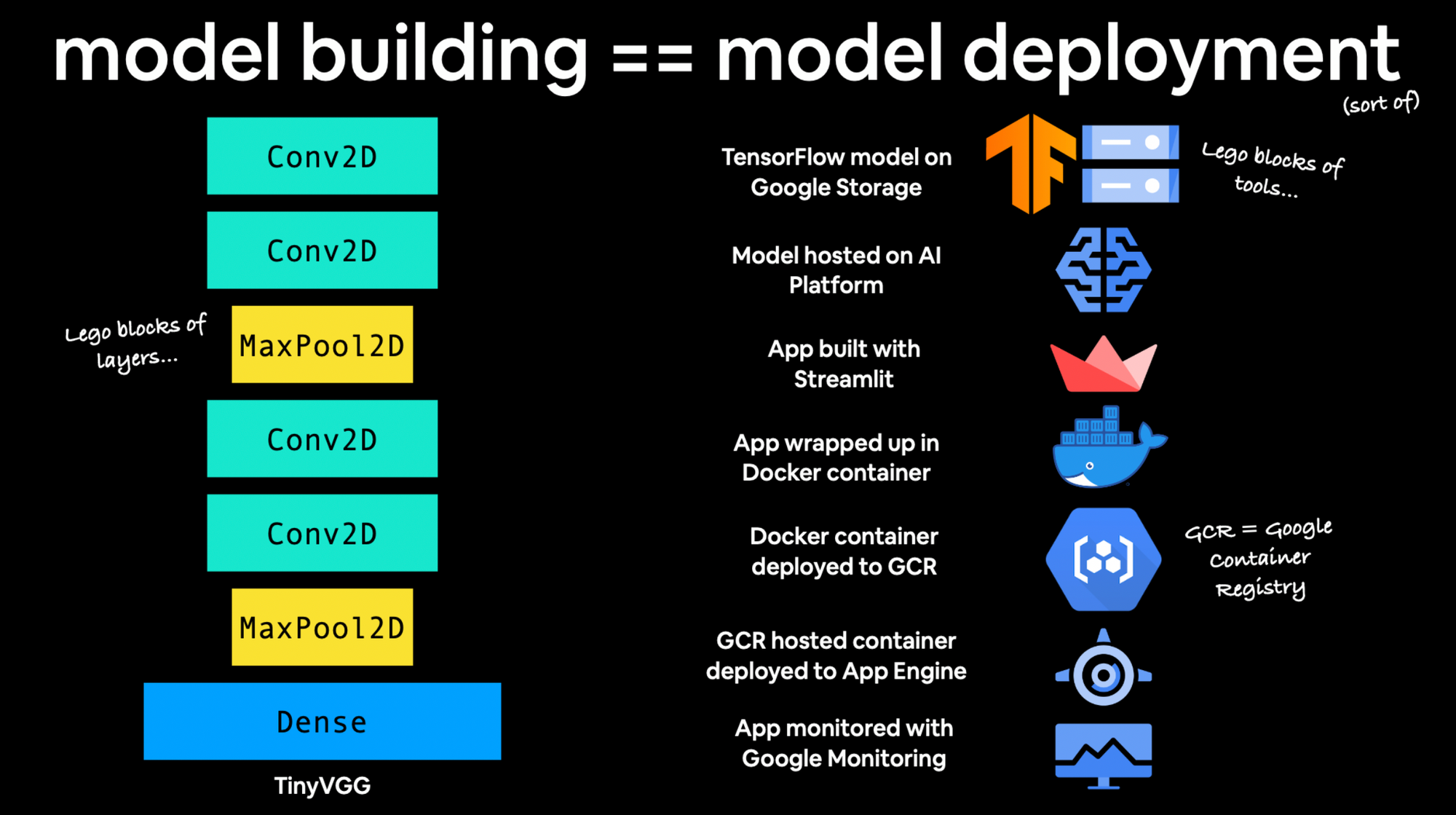
Machine learning deployment is similar to machine learning model building
For model building (at least in deep learning) you stack together different layers until you get the outcome you desire. For machine learning deployment, you stack together different cloud services until you get the outcome you desire. Both are like building with legos.
When you first starting building machine learning models, there are a bunch of terms and words you’d never heard of, the same goes with deploying (getting them into the hands of others) models, it’s just another bunch of terms you haven’t heard of (yet).
Your holy grail (the holy grail of any ML system) is a data flywheel
If you’re like me, you learned machine learning on static datasets, however, data in the real-world is rarely static, it’s constantly changing.
So how do you build your applications with this mind?
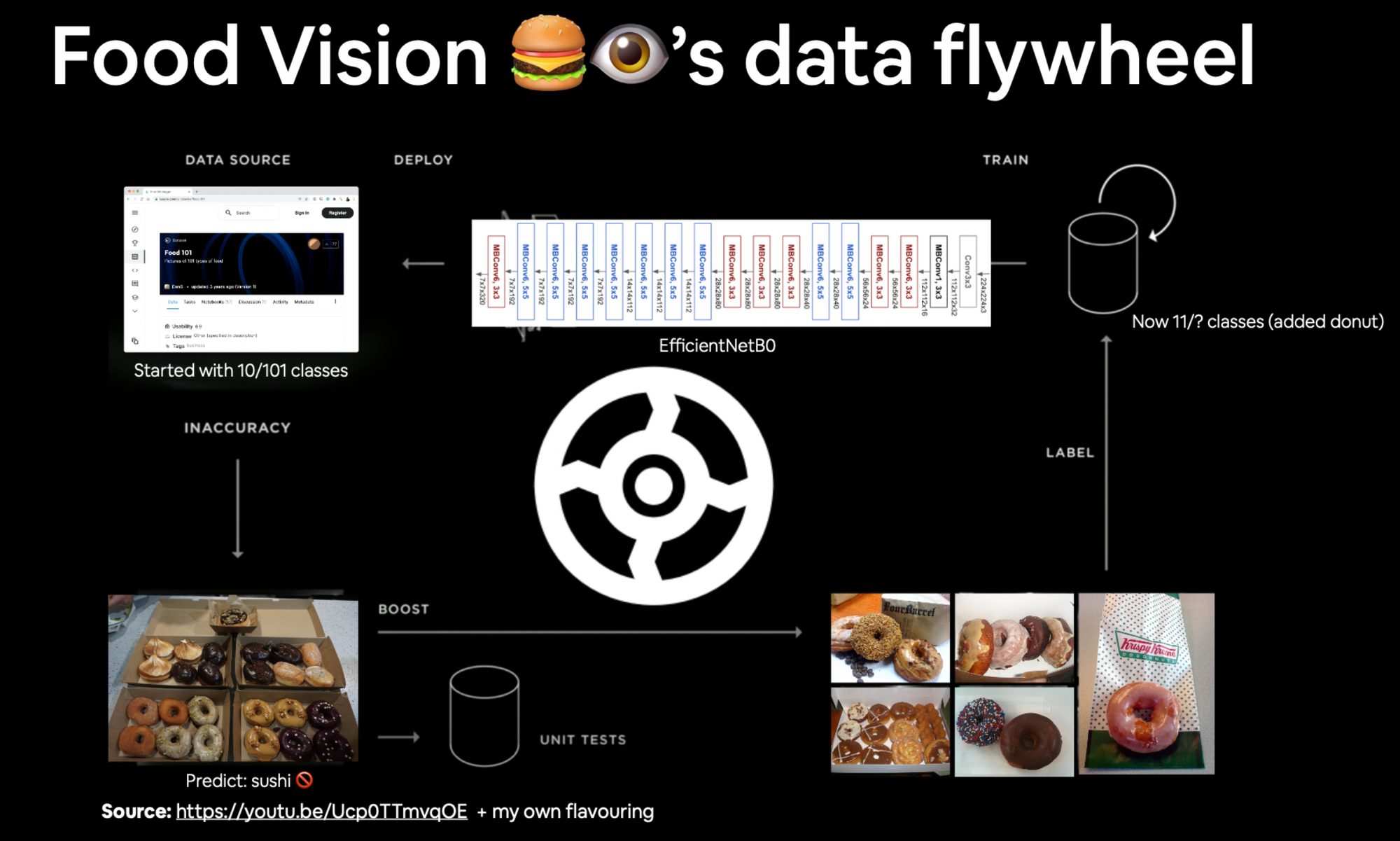
Credit to Josh Tobin for the term "data flywheel".
What do you do when (not if) your machine learning model fails?
This ties into the point above. Your model is eventually going to fail.
How does this look to someone using it?
How do you design for model failures? And better yet, how can you use those failures to help improve future models (data flywheel).
I tried to tackle all of these through the narrative of building and deploying (to Google Cloud) an application to classify different images of food (Food Vision 🍔👁).
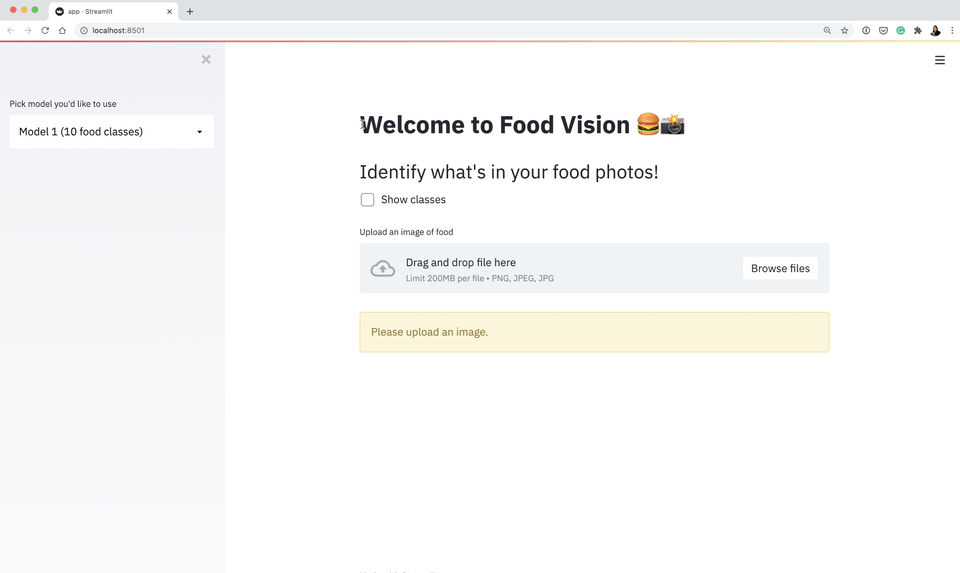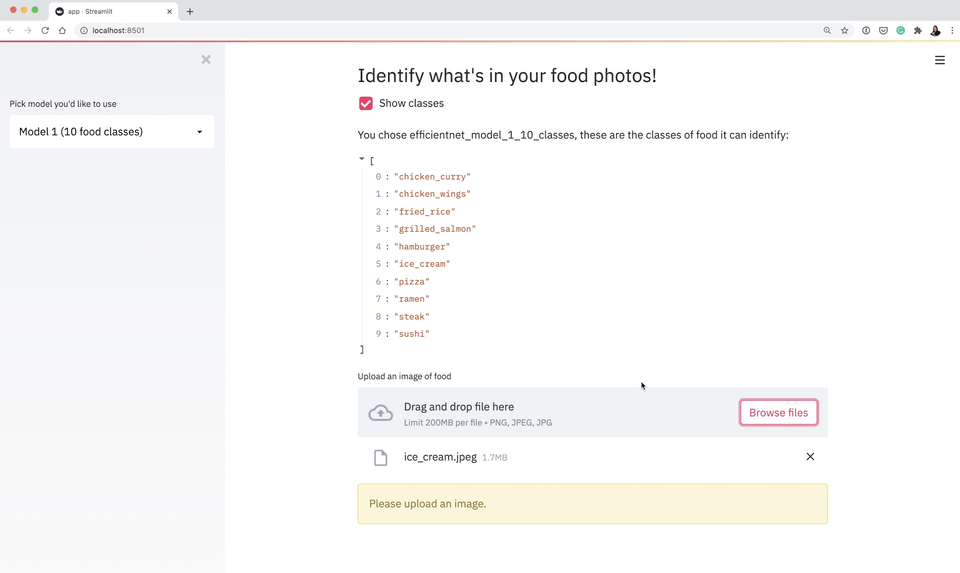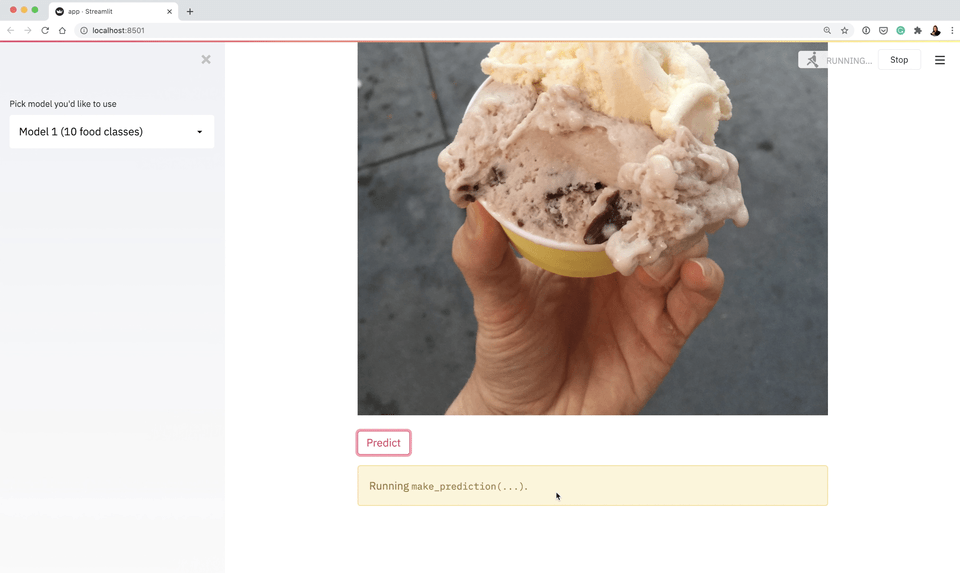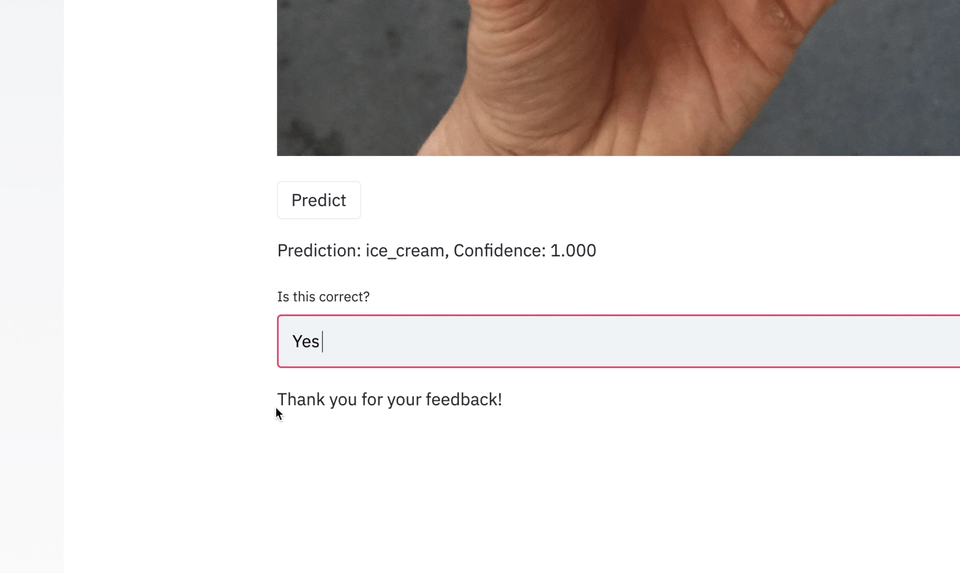
All of the materials are publicly available.
- Get the Food Vision code on GitHub (the README has step by step instructions for the tutorial)
- See the pretty slides
- Watch the full CS329s Machine Learning Model Deployment for 20% Software Engineers on YouTube (I may have gone overtime during the live tutorial but the beauty of YouTube is: there’s no time limit, so I included the things I missed)
Thank you thank you thank you to Chip and the CS329s students for the opportunity and incredible questions.
And to Ashik Shafi for tuning into the Twitch livestreams and telling me what was confusing when drafting materials.
PS, if you’d like to learn more about the crossover of machine learning and software engineering, I’d recommend the following posts/blogs:
- Mark Douthwaite's outstanding ML + software engineering blog
- Lj Miranda's amazing post on software engineering tools for data scientists
- Chip Huyen's thorough exploration of the MLOps tool space