A Quick Introduction to PyTorch 2.0
PyTorch 2.0 is out! And it comes with plenty of updates. Also NVIDIA GTC March 2023 is around the corner, to celebrate they've given me an RTX 4080 to giveaway!


- See the video version of this article on YouTube
- GPU giveaway details are at the bottom of the article
- You can install PyTorch 2.0 via the PyTorch getting started page
- (WIP) See my PyTorch 2.0 code tutorial on learnpytorch.io
30-second intro
The official version of PyTorch 2.0 comes out today (March 15 2023)!
With the main improvement being speed.
This comes via a single backwards-compatible line.
torch.compile()
In other words, after you create your model, you can pass it to torch.compile() to recieve a compiled model and in turn expect speedups in training and inference on newer GPUs.
Before PyTorch 2.0
import torch
model = create_model()
### Train model ###
### Test model ###After PyTorch 2.0
import torch
model = create_model()
compiled_model = torch.compile(model) # <- new!
### Train model ### <- faster!
### Test model ### <- faster!torch.compile() which does a bunch of behind-the-scenes optimizations to make your models faster.Speedups
But these are just words, how much faster is it actually?
The PyTorch team ran tests across 163 open-source models from Hugging Face Transformers, timm (PyTorch Image Models) and TorchBench (a curated set of popular code bases from across GitHub).
This is important because unless PyTorch 2.0 is faster on models people actually use, it’s not faster.
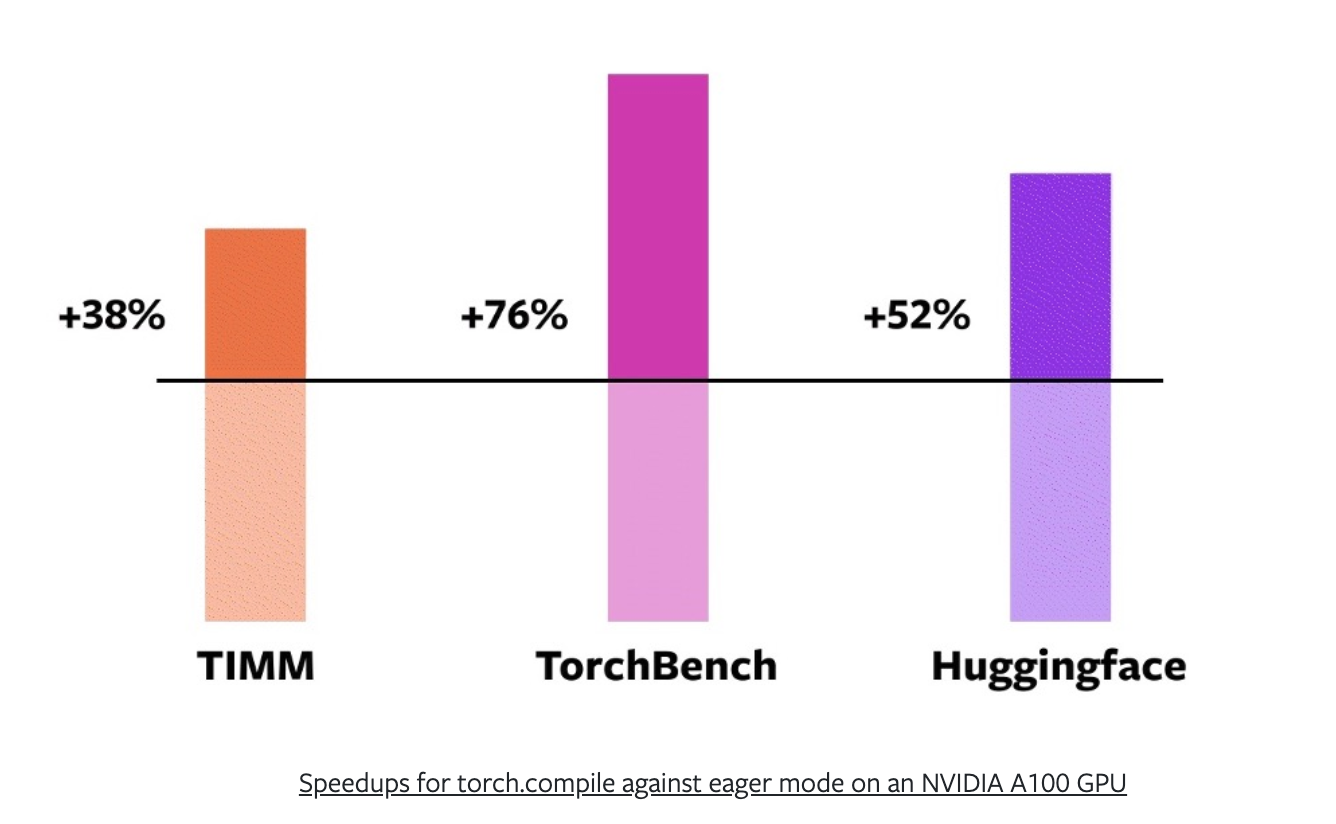
Using a mixture of AMP (automatic mixed precision or float16) training and float32 precision (higher precision requires more compute) the PyTorch team found that torch.compile() provides an average speedup of 43% in training on a NVIDIA A100 GPU.
Or 38% on timm, 76% on TorchBench and 52% on Hugging Face Transformers.
Naturally, I tried torch.compile() in one of my own benchmarks:
I tried a ResNet50 model from torchvision on the CIFAR10 dataset with a batch size of 128 and an image size of 224 for 3 runs of 5 epochs.
It seems torch.compile() is definitely better when you're using more of the GPU, e.g. larger batch sizes and data sizes.
I noticed the first epoch was slower but subsequent epochs went faster across both my local RTX 4080 GPU and an A100 GPU on Google Colab.
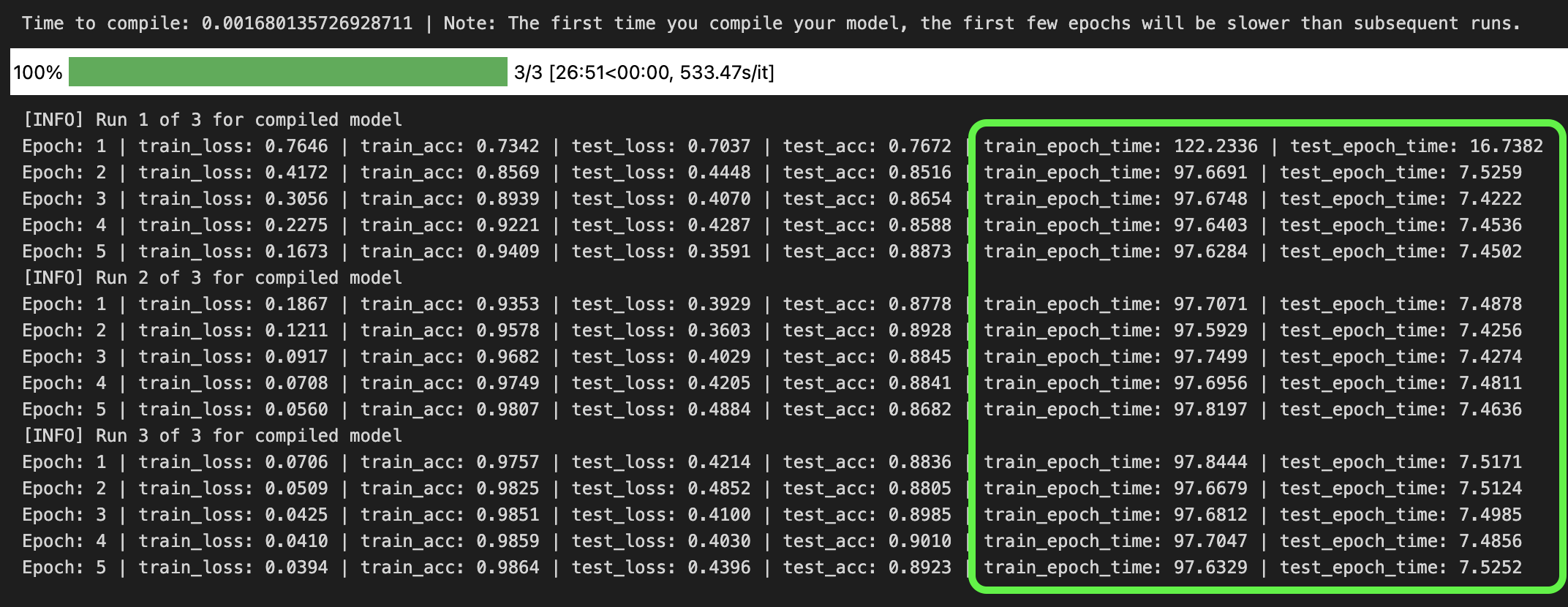
torch.compile() the first epoch will tend to take longer then subsequent epochs. This is because PyTorch is optimizing the model behind the scenes via techniques such as operator fusion and graph capture. See the code I used for the benchmarks on the PyTorch Deep Learning GitHub. My speedups weren’t as large as reported in the PyTorch 2.0 release notes, however, they were still around 10% on training epochs.
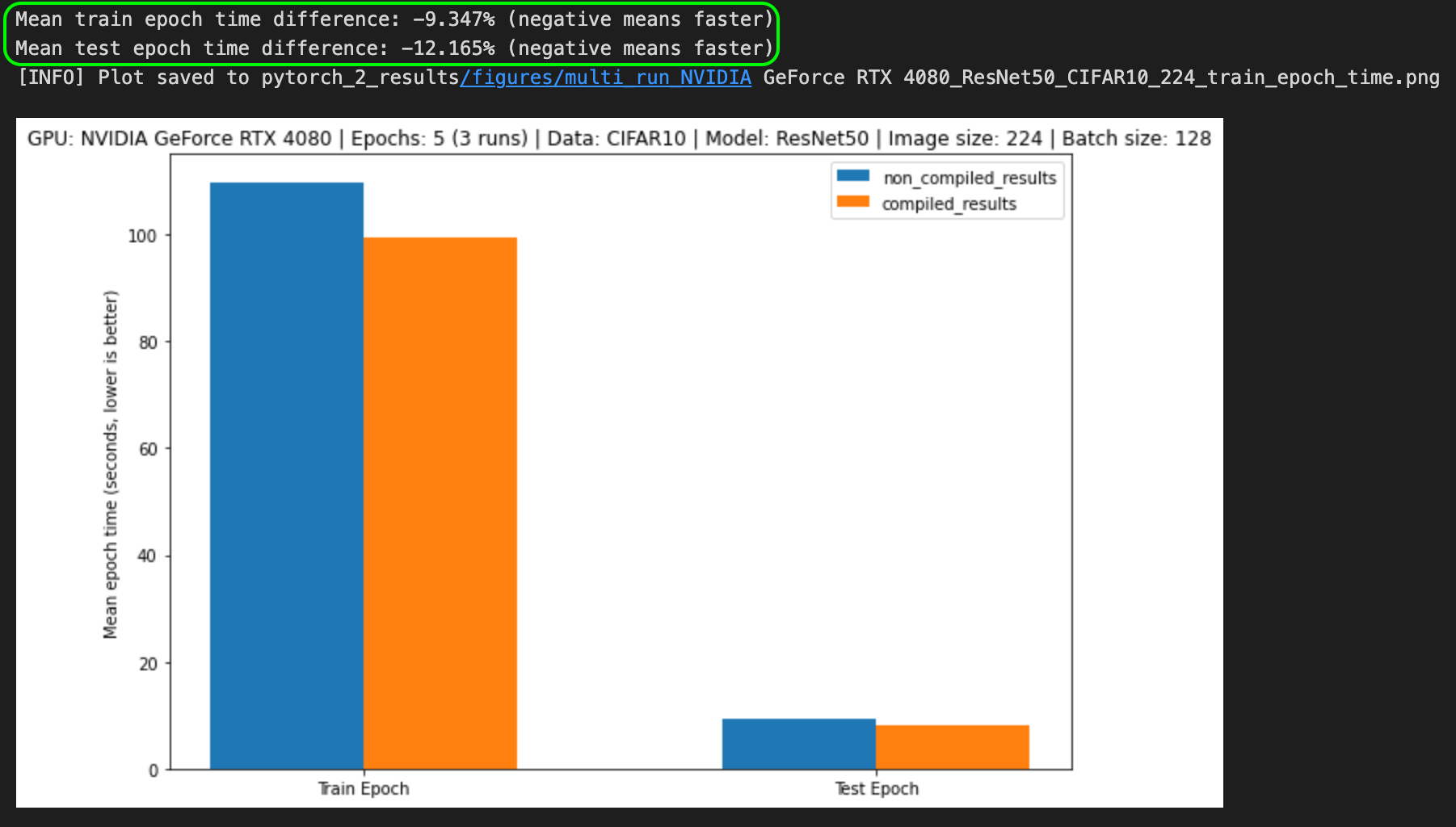
But I’m yet to explore mixed precision training or transformer-like architectures (which have the biggest speedups), higher batch sizes, longer training runs (where torch.compile() would probably be most effective).
3-minute intro
What's happening behind the scenes of torch.compile()?
torch.compile() is designed to "just work" but there are a few technologies behind it:
- TorchDynamo
- AOTAutograd
- PrimTorch
- TorchInductor
The PyTorch 2.0 release notes explain these in more detail but from a high level the two main improvements torch.compile() offers are:
- Fusion (or operator fusion)
- Graph capture (or graph tracing)
Fusion
Fusion, also known as operator fusion is one of the best ways to make deep learning models go brrrrrr.
Operator fusion condenses (like Dragon Ball Z) many operations into one (or many to less).
Why?
Modern GPUs have so much compute power they are often not compute limited, as in, the main bottleneck to training models is how fast can you get data from your CPU to your GPU.
This is known as bandwidth or memory bandwidth.
You want to reduce your bandwidth costs as much as possible.
And feed the data hungry GPUs with as much data as possible.
So instead of performing an operation on a piece of data and then saving the result to memory (increased bandwidth costs), you chain together as many operations as possible via fusion.
A rough analogy would be using a blender to make a smoothie.
Most blenders are good at blending things (like GPUs are good at performing matrix multiplications).
Using a blender without operator fusion would be like adding each ingredient one by one and blending each time a new ingredient is added.
Not only is this insane, it increases your bandwidth cost.
The actual blending is fast each time (like GPU computations generally are) but you lose a bunch of time adding each ingredient one by one.
Using a blender with operator fusion is akin to using a blender by adding all the ingredients at the start (operator fusion) and then performing the blend once.
You lose a little time adding at the start but you gain all of the lost memory bandwidth time back.
Graph capture
Graph capture I’m less confident explaining.
But the way I think about is that graph capture or graph tracing is:
- Going through a series of operations that need to happen, such as the operations in a neural network.
- And capturing or tracing what needs to happen ahead of time.
Computing without graph capture is like going to a new area and following GPS directions turn by turn.
As a good human driver, you can follow the turns quite easily but you still have to think about each turn you take.
This is the equivalent to PyTorch having to look up what each operation does as it does it.
As in, to perform an addition, it has to look up what an addition does before it can perform it.
It does this quickly but there’s still non-zero overhead.
Computing with graph capture is like driving through your own neighbourhood.
You barely think about what turns to make.
Sometimes you get out of the car and realise you can’t remember the last 5 minutes of the drive.
Your brain was functioning on autopilot, minimal overhead.
However, it took you some time upfront to remember how to drive to your house.
This is a caveat of graph capture, it takes a little time upfront to memorize the operations that need to happen but subsequent computations should be faster.
Of course, this is a quick high-level overview of what’s happening behind the scenes of torch.compile()but it's how I understand it.
For more on fusion and graph tracing, I’d recommend Horace He’s Making Deep Learning Go Brrrr From First Principles blog post.
Other notable PyTorch 2.0 releases
There are plenty of other notable PyTorch 2.0 releases, such as:
- Faster Transformers is now in stable condition, which means that models that use the transformer-style of architecture or scaled-dot product attention should be faster.
- Universal device setup is now possible thanks to a context manager or global setting.
import torch
torch.set_default_device('cuda')
layer = torch.nn.Linear(20, 30)
print(layer.weight.device)
print(layer(torch.randn(128, 20)).device)
>>> cuda:0
>>> cuda:0
- A bunch of updated MPS (metal performance shaders) operations improves PyTorch coverage for Mac.
PyTorch 2.0 domain library releases
There's also a bunch of domain library upgrades to go along with PyTorch 2.0 in TorchVision, TorchText, TorchRec, TorchAudio and more.
Two of my favourites include:
- TorchVision
transformsnow extend to object detection, segmentation and video classification (not just image classification). - TorchText now supports in-built T5 and Flan-T5 models (two incredibly good language models).
Caveats
Something to note is that although PyTorch 2.0 is considered a stable release, there are still a few caveats, such as:
- Speedups with
torch.compile()are typically more seen with server class GPUs such as A100s than desktop GPUs such as RTX 3090s and RTX 4090s. - There are some limitations to exporting compiled models, however, these should be fixed in future releases.
Resources to learn more
To learn more about all of the updates to PyTorch 2.0 (and there’s a lot), I’d recommend checking out the following:
- PyTorch 2.0 technical overview
- PyTorch 2.0 Release Notes (blog post)
- PyTorch 2.0 Release Notes (GitHub)
- Trying PyTorch 2.0 on multiple models from TIMM and Hugging Face
- PyTorch domain library updates
- PyTorch speedups on Diffusers (a Hugging Face library for Stable Diffusion)
- Which GPU to get for deep learning? by Tim Dettmers (this includes a lot of great info of the how the newer GPU hardware enables faster computing)
- Example PyTorch 2.0 notebook with benchmarks (my own PyTorch 2.0 notebook benchmarking code, hackable to change datasets/models)
NVIDIA RTX 4080 and Deep Learning Institute Credit Giveaway
To celebrate NVIDIA GTC March 2023, NVIDIA has been so kind to give me a brand new RTX 4080 and five Deep Learning Institute (DLI) credits to giveaway.

And it so happened to be perfect timing with the release of PyTorch 2.0.
So how do you enter?
To be eligible for the giveaway requires 3 steps:
- Sign up for NVIDIA GTC March 2023 (free).
- Follow @mrdbourke (me) on Twitter.
- Retweet this tweet (see below) during NVIDIA GTC March 2023 (between March 20-23) with your favourite moment or a screenshot of you attending a session at NVIDIA GTC with the hashtag "#GTC23".
To celebrate #GTC23 @nvidia has sent me an RTX 4080 + 5 DLI credits to giveaway!
— Daniel Bourke (@mrdbourke) March 17, 2023
To win:
1. Sign up for GTC 2023 - https://t.co/MRVPw8z1CS
2. Follow me
3. Retweet this tweet during GTC (March 20-23) with a screenshot or something you've learned from a session. pic.twitter.com/0dqP8TMhVU
For example, you could write something like the following:
Loving learning about the new FP8 training techniques available in Hugging Face Accelerate at NVIDIA #GTC23!
That's it!
Winners will be drawn on March 30 2023 (one week after NVIDIA GTC) and I will post the updates here/on Twitter.
Make sure you have your Twitter DM's open so I can message you!
Give away terms & conditions
Winners will be chosen at random based on my Twitter followers, similar to the levels.io giveaway.
If I message you on Twitter, you'll have 48 hours to respond before I pick another winner.
If you win the RTX 4080, I will mail it to you anywhere in the world, this means I'll need your address (or an address I can send it to). I can send tracking numbers but I'm not responsible if it gets lost in transit.
The RTX 4080 I send will be brand new and unboxed (not the one in my computer).
It would also be cool to see a photo of when you receive the GPU so I could post it here.
For the five DLI credits, 1 credit = 1 course on the Deep Learning Institute.
NVIDIA GTC sessions I'm going to
Looking at the NVIDIA GTC 2023 session catalogue, there's a lot to choose from!
I've looked through them and picked out a few I'm excited for:
- Compile and train with 43% speedup using PyTorch 2.0
- Fireside Chat with Ilya Sutskever and Jensen Huang: AI Today and Vision of the Future
- Exploring next-generation methods for optimizing PyTorch models for inference with Torch-TensorRT
- FP8 Mixed-Precision Training with Hugging Face Accelerate
- Generative AI Demystified
Enjoy the PyTorch 2.0 speedups!
And see you at GTC 2023!
If you have any questions, feel free to leave a comment below or on the video version of this article.