Copying Tesla's Data Engine (for food images)
A cooking recipe for building Nutrify's data engine.

I’m working on a full-stack machine learning application with my brother called Nutrify.
The tagline is: take a photo of food and learn about it.
Ideally, it’ll work like magic!
Of which the magic is really machine learning.
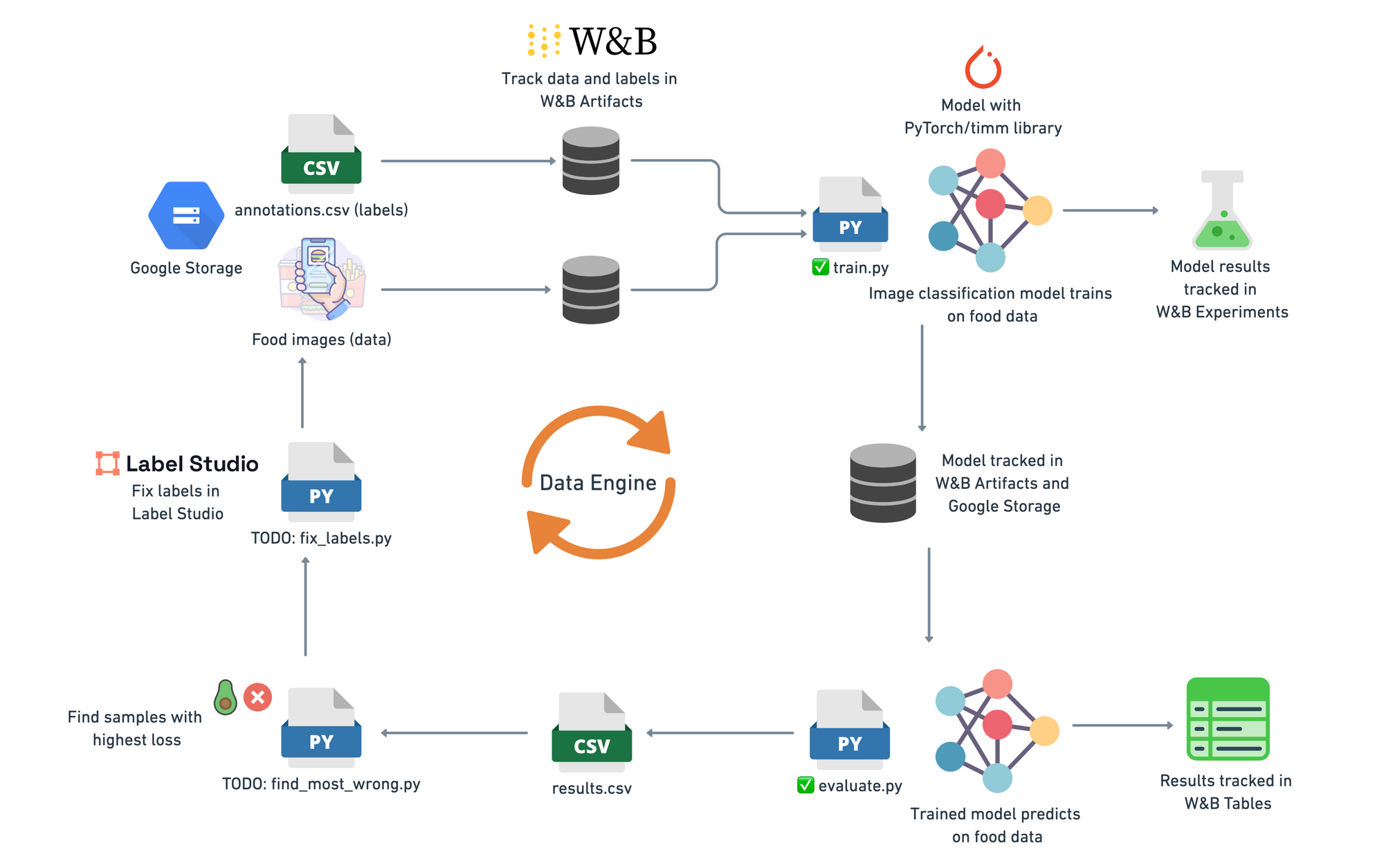
The current goal is to build a data flywheel.
Or a data engine (depending on what reference you’re using).
I’m basically copying Tesla’s data engine graphic from their 2021 AI day presentation and making it work for images of food.
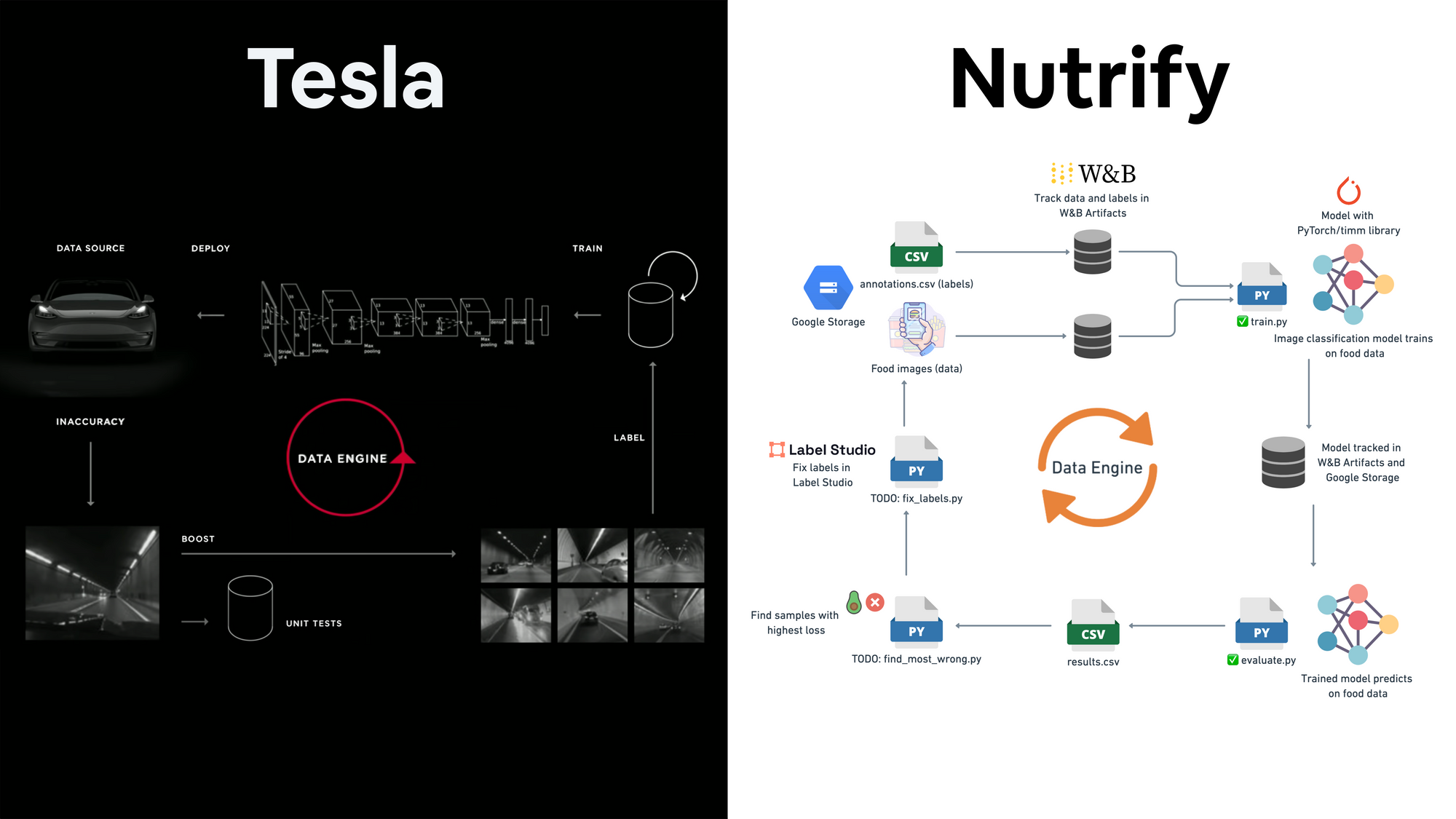
In short, since the performance of your machine learning model depends on data, the idea of a data engine is to: continually improve your training data to continually improve your model.
This post reads like a cooking recipe for what’s happening on the machine learning side of things (my brother is working on the iOS app).
The specific details can be found in the code on GitHub.
The outline consists of a few major parts:
- Data source (food images and annotations)
- Data tracking (what data gets used, when?)
- Model training (image classification computer vision models)
- Experiment tracking (which model performed the best?)
- Model evaluation and tracking
- Find the inaccuracies (most wrong)
- Correct the inaccuracies (relabelling, manual and auto)
- Add the fixed samples back into the data source
- Repeat
Notice the trend: almost everything is tracked/versioned.
I want to at any point and time find out what model was trained on what data and what labels.
Note: This is the first time I’ve built something like this so it’s more like a work-in-progress taped together mess than a polished production system.
You can see a video version of this article (plus a little bit more) on YouTube:
Data source
Ingredients: Streamlit, manually uploaded images, Google Sheets, Microsoft Bing Image Search API
The current data source contains images of 199 classes of food (originally 200 but I removed a duplicate).
{
"0": "almond_butter",
"1": "almonds",
"2": "apple",
...
"196": "white_wine",
"197": "yoghurt",
"198": "zucchini"
}
There’s about 100-150 images of each class with an 80/20 training and test split resulting in 20,000 training images and 5,000 testing images.
I’m working with a small(ish) dataset to begin because I’d like my experiments to be fast.
Once the overall workflow is fleshed out, more data can be added.
Where did the classes come from?
The classes came from me taking photos of what I’ve eaten and then manually uploading the images to Google Storage and saving the text annotations (e.g. “eggs, bacon, toast”) to Google Sheets.
I then cleaned the manually uploaded image descriptions and pulled out the top 200 foods I’ve consumed over the last year or so.
Using these class names, I downloaded images from the internet using the Microsoft Bing Image Search API.
The search term serves as the image classification label (one image, one label).
One clear limitation of my dataset right now is that it only contains classes of foods I've personally taken photos of.
So Nutrify's capabilities are currently biased towards what I eat.
Future datasets will likely be a combination of:
- Filtering large open source datasets for a more diverse range of food images such as those available on Hugging Face Datasets.
- Manually curated images of food (future versions of Nutrify may just automatically save every image uploaded).
Data and label tracking
Ingredients: Weights & Biases Artifacts, Google Storage
To make experiments reproducible: everything gets tracked or versioned.
Data (food images) and annotations/labels (a CSV file mapping unique image ID’s to their appropriate label) get tracked with Weights & Biases Artifacts.
Since images are all stored in Google Storage, to prevent replicating data, Artifacts treats the Google Storage Bucket as a reference (images stay on Google Storage and Artifacts tracks their URLs) and after initial setup only checks for changes.
The same goes for the labels.
For example, if I create an Artifact of data and labels and then run 10 experiments without any changes to the data and labels, all 10 experiments will use the same data and labels.
However, if I add an extra 100 images and their associated labels, the next experiment will then use the updated data and labels (as long as I tell Artifacts to always pull the latest version with the :latest suffix).
# Example of what the latest suffix looks like for an Artifact
mrdbourke/WANDB_PROJECT/food_vision_labels:latestDoing this means every modelling experiment (also tracked with Weights & Biases) has an input and output Artifact lineage:
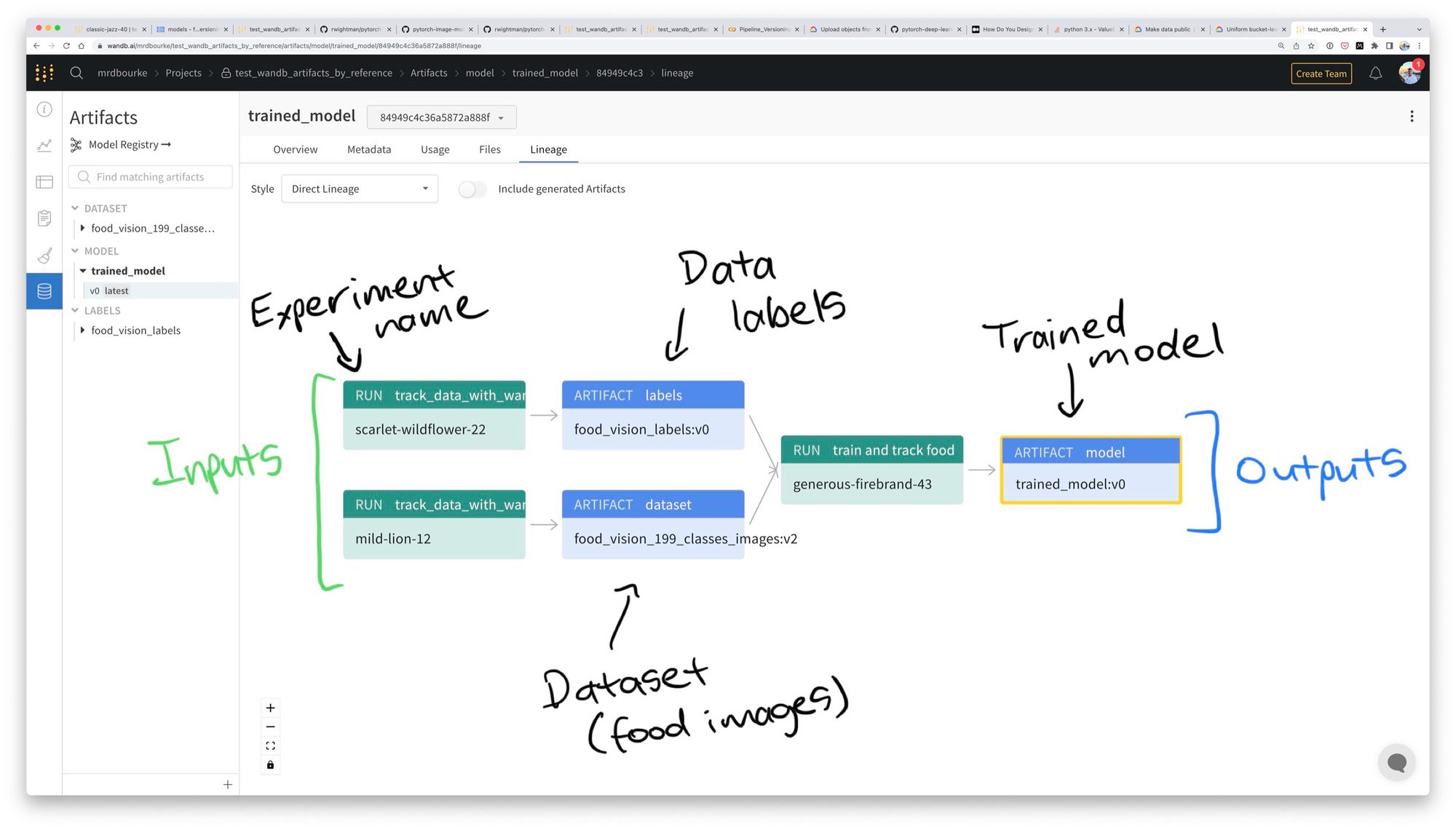
This is paramount because one of the fundamental concepts of machine learning is: what are your ideal inputs and outputs?
In Nutrify’s case the inputs are images of food (pixels) and the outputs are text labels of what food(s) is/are in the image.
More on the output Artifacts later.
Model training
- Ingredients:
timmlibrary (PyTorch Image Models), NVIDIA TITAN RTX - Code:
train.py
Nutrify currently runs two models:
- FoodNotFood – a binary image classification model to classify whether the image is of food or not.
- FoodVision – a multi-class image classification model to classify what kind of food is in the image.
One image goes in and if it passes through the FoodNotFood model, it gets passed to FoodVision and one of many (currently 199 total classes) comes out.
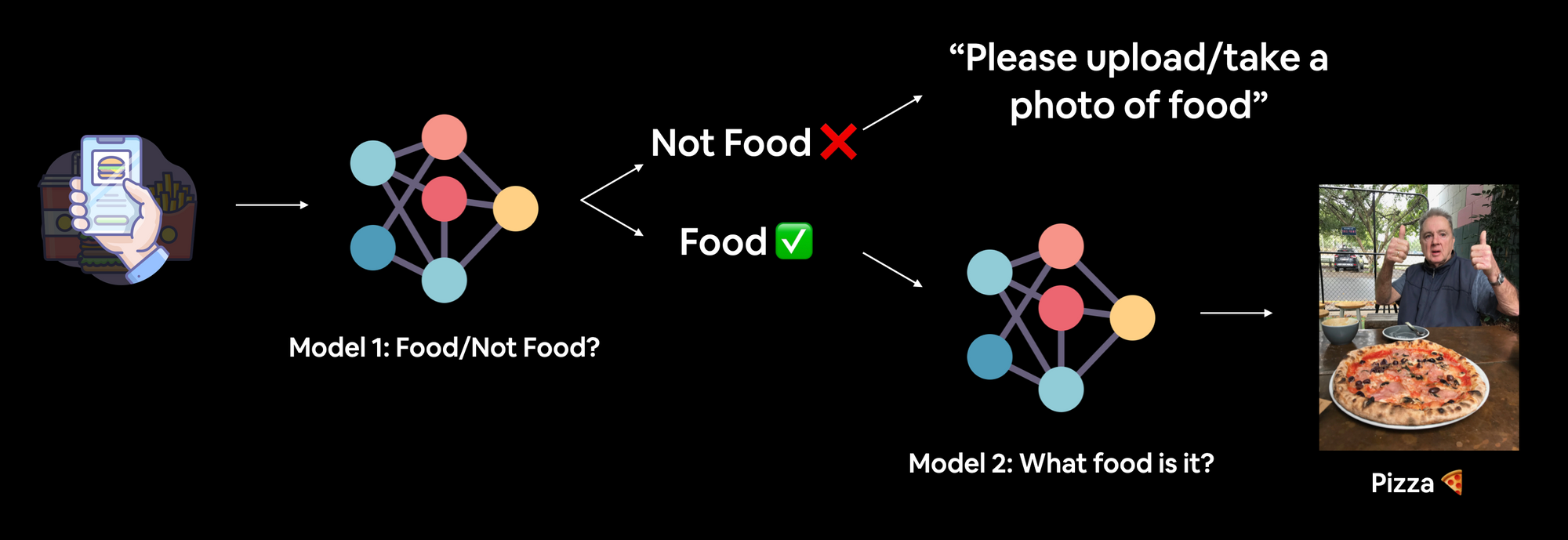
Of course, this breaks when there's more than one food in the image (e.g. multiple fruits in a fruit bowl or a dish) but this is on purpose.
If I can’t create the data engine with image classification, how can I expect to create it with something more complex like object detection or segmentation?
Pretrained computer vision models have become commodities so my model creation code is a single Python function.
The FoodVision training script (train.py) is a hacked together modified and scaled-down version of the timm (PyTorch Image Models) libraries’ training script.
In essence, I take a pretrained PyTorch computer vision model from the timm library, replace the top layer to suit my number of classes and then freeze the base layers and only train the output layer.
This process is known in machine learning as transfer learning, taking what one model has learned on another dataset and applying it to your own.
All training happens on a local deep learning PC I built with a friend powered by a NVIDIA TITAN RTX.
Future updates:
- Use the same backbone for multiple outputs, for example, one image encoder leads to two or more heads (FoodNotFood and FoodVision in one model).
- Predict more attributes of the image, for example, "one food or multiple", "clear image or confusing", "whole food or dish", similar to Alex Nichol's blog post on predicting different attributes of cars.
- Multiple models through different functions, for example, small, big, and large for different use cases.
- Go from image classification model to object detection to segmentation to possibly even image-to-text retrieval (similarity matching).
Experiment tracking (for training)
- Ingredients: Weights & Biases Experiments
- Code:
train.py
Model training gets tracked with Weights & Biases Experiments.
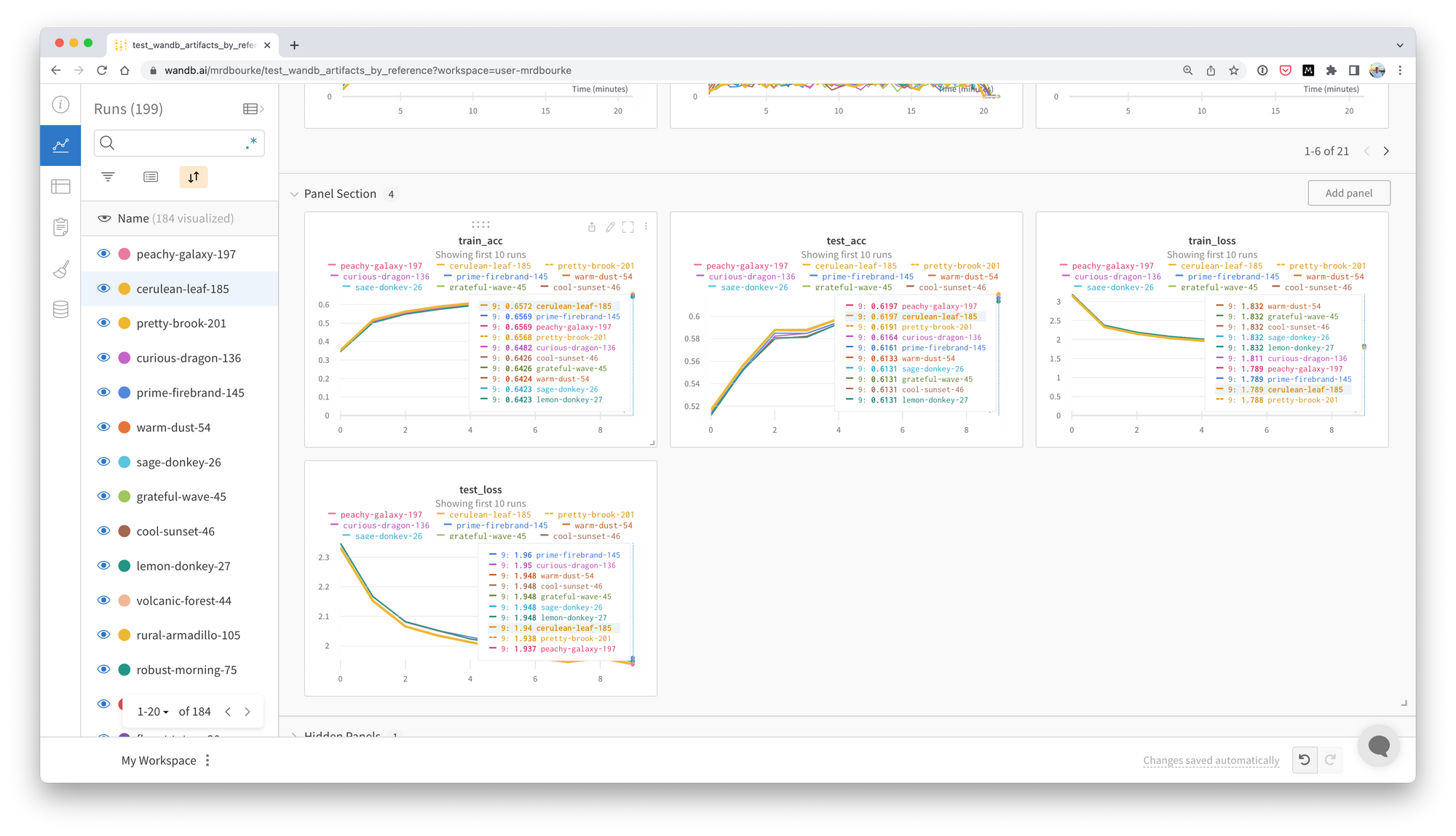
Experiments are kept short (for now), 10 epochs max, right now fine-tuning the last layer of a model trained on ImageNet.
“Experiment, experiment, experiment!”
The model I’m currently using is "coatnext_nano_rw_224" from timm, not too big, not too small.
This keeps 10 epochs of training to about ~20 minutes on my NVIDIA Titan RTX GPU with a batch size of 128.
I haven’t tried many other models yet but you could easily sub any of the EfficientNetBX or ConvNeXt variants into what I’m doing.
Bigger models and longer training sessions can come once the overall workflow of the data engine is put together.
Future updates:
- Once the data engine is working, I’d like to be training at least one new deployable model per day (potentially more).
- Training a bigger model could also be used for helping with the automatic labelling pipeline.
- Hyperparameter search, right now I've been using the same static learning rate and hyperparameters for each run, this could definitely be improved.
Model evaluating and tracking
- Ingredients: Weights & Biases Tables
- Code:
evaluate.py
I’ve got a Python script called evaluate.py which runs similar code to the training script but is focused on making predictions on images and then logging various details about each prediction.
[{'image_path': 'artifacts/food_vision_199_classes_images:v2/97b455c2-4541-46bb-bcdb-b7f967804efa.jpg',
'pred_label': 149,
'pred_prob': 0.9920064806938171,
'pred_class': 'ramen',
'top_n_preds': [{'pred_prob': 0.9920064806938171,
'pred_label': 149,
'pred_class': 'ramen'},
{'pred_prob': 0.0029560404364019632,
'pred_label': 112,
'pred_class': 'noodles'},
...],
'image_name': '97b455c2-4541-46bb-bcdb-b7f967804efa.jpg',
'true_label': 109,
'true_class': 'miso_soup',
'pred_correct': False,
'pred_in_top_n': True,
'image': <wandb.sdk.data_types.image.Image at 0x7f0bcc47c880>}]These predictions are saved as a CSV and logged and tracked in Weights & Biases Tables for visual inspection.
Future updates:
- I'd like a way to automatically tag my "best" model in Weights & Biases based on several metrics, for example, lowest test loss. That way I could automatically use it in other pipelines/deploy it. I'm sure this is possible but I haven't figured it out yet.
Finding the inaccuracies (most wrong)
- Ingredients: Weights & Biases Tables
- Code:
evaluate.py
Normal software development involves bug fixing in code.
Machine learning involves bug fixing in code and in data.
In Nutrify’s case, two main bugs in the data are:
- Ground truth label doesn’t match what’s in the image (for example the label is "apple" but that photo is of a banana).
- Ground truth label could better represent what’s in the image (for example, the label is "potato" but it could be "mashed potato").
Data bugs are different to model bugs.
A model bug (or error) would be when the model makes an incorrect prediction.
For example, predicting pizza when the right prediction is pasta.
One of the main ideas of data-centric machine learning is to let the model do the work for you.
As in, there’s no way you could go through all the data yourself, so let the model go through it for you.
To find the errors in Nutrify’s dataset, the current workflow is to:
- Take the model’s evaluation results (from
evaluate.py). - Sort them to show the top-N (e.g. top 100) examples where the model is highly confident (high prediction probability) but the prediction is wrong (I refer to these examples as "most wrong").
- Track the "most wrong" examples in Weights & Biases Tables for further inspection.
You could do the same for the loss values as well, find the sample predictions with the highest loss.
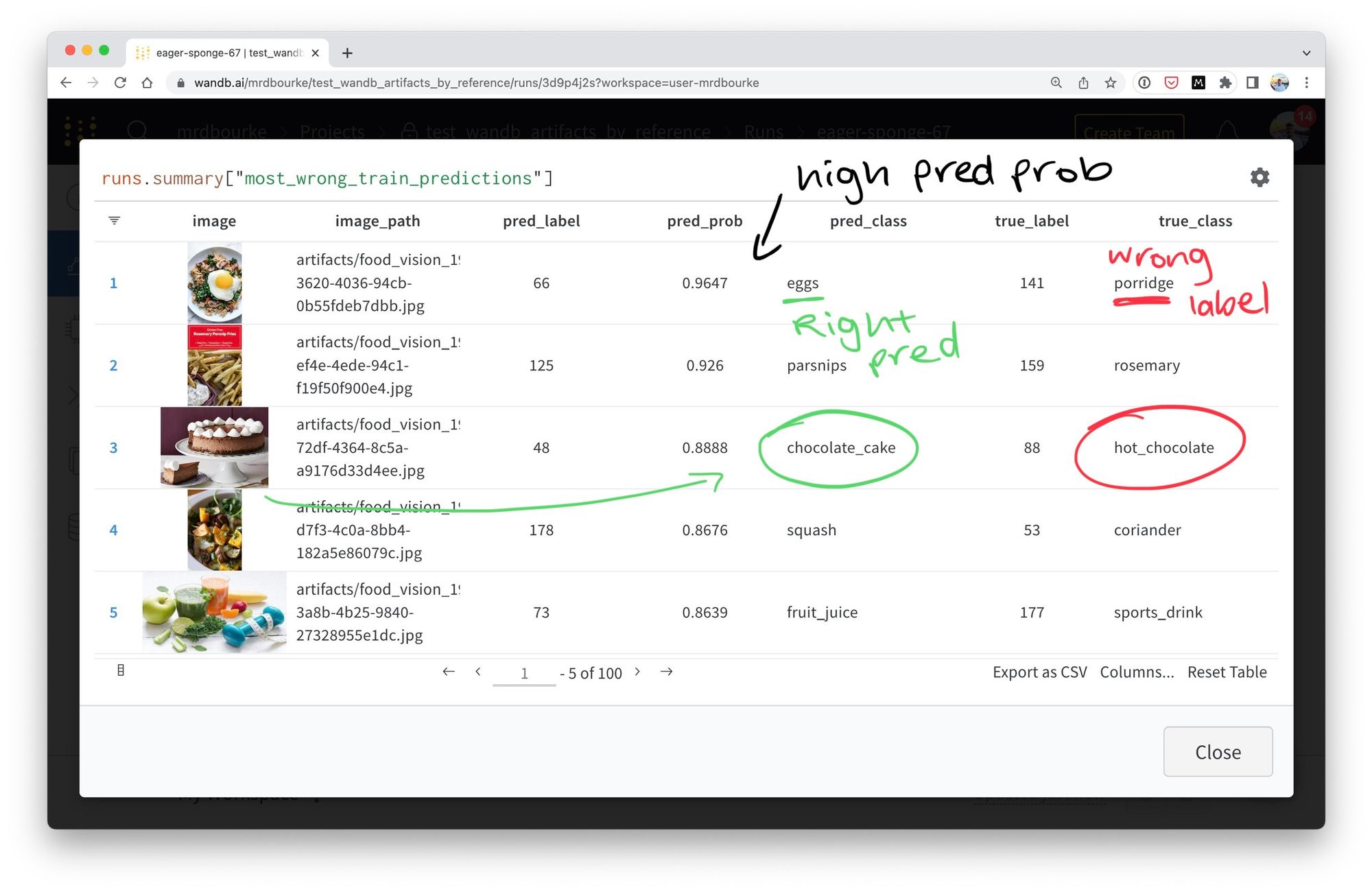
Once the most wrong samples have been discovered, they can be fixed/improved/removed to potentially improve the overall quality of the dataset.
And because the model trains on the dataset, improving its label quality hopefully results in a better model.
Correcting the inaccuracies
- Ingredients: Label Studio
- Code:
fix_labels.py
To correct the inaccuracies, I programmatically pass (using fix_labels.py) the top-N most wrong samples to Label Studio, an open-source labelling program.
Label Studio allows you to create a labelling interface programmatically.
I found a similar workflow to what I was wanting to do in a YouTube video by Modzy so I copied their setup and made it suitable for my own.
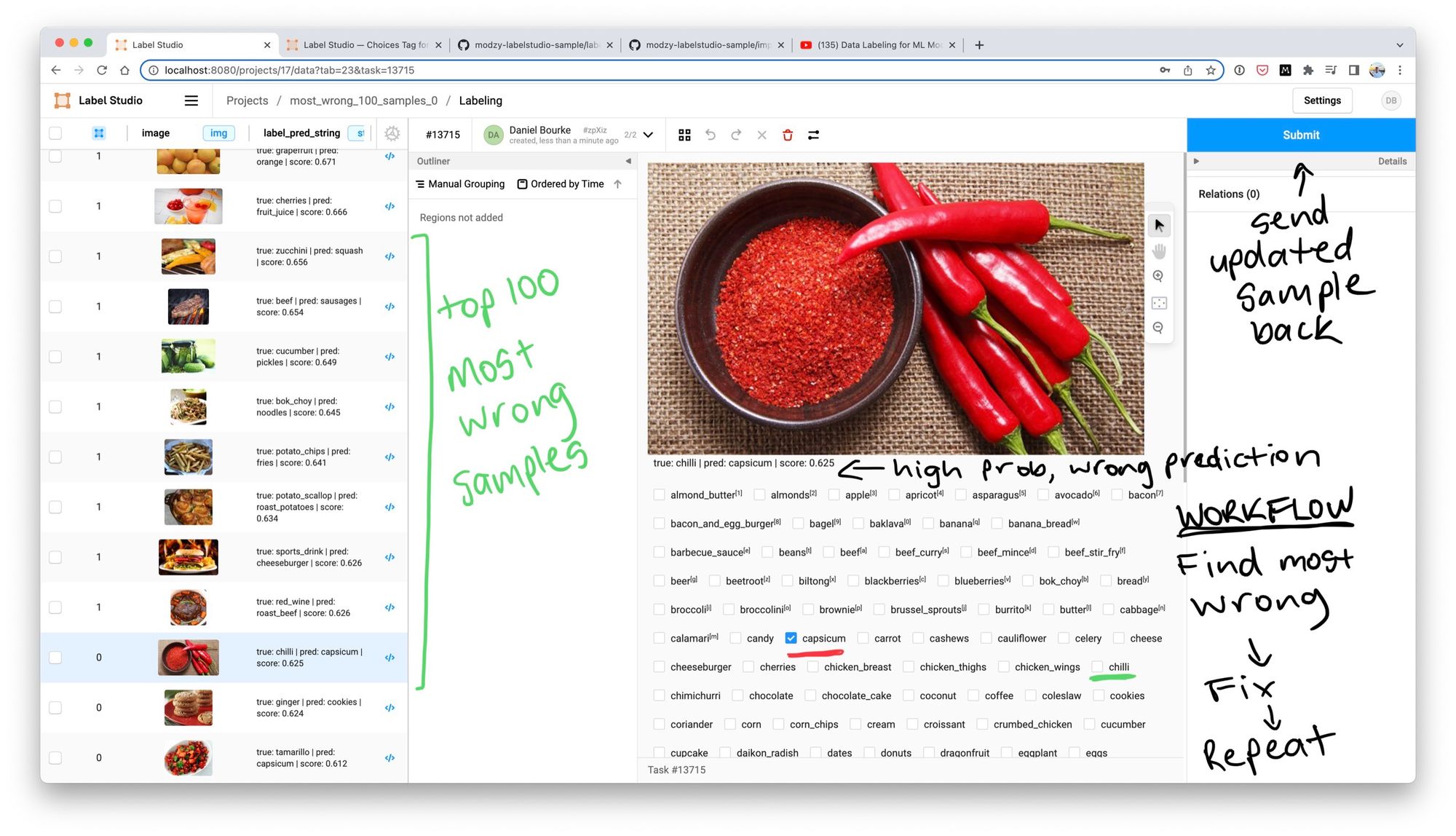
The labelling interface shows the ground truth label, the predicted label and the prediction probability.
Right now, I’m correcting inaccuracies by hand.
But I’m a programmer not a factory line worker.
I love food but I’m not going to sit there all day correcting labels.
So I always ask: is there a model that could automate what I’m doing?
Future ideas for the label correction pipeline:
- Could a combination of language models, vision-language models and VQA (visual question answering) models reproduce what I'm doing by hand?
- Automate the easy ones (with vision-language models) and send the hard ones to a human (me), this process is often referred to as active learning or “human-in-the-loop” learning.
- The recent CiT Paper (Curation in Training) has gotten me very excited because it could potentially take care of the above two steps.
Add the fixed samples back into the data source
- Ingredients: Label Studio, Google Storage
- Code: (coming soon)
After correcting the labels, Label Studio offers an option to export the annotations as a JSON.
I then match up the updated labels with the unique image ID in the original labels and merge the ones marked for correction.
For now, this is a very manual process (in a cell-by-cell notebook with nowhere near enough tests) but just like the training and evaluation scripts, I’ll be looking to automate the merging of updated labels in the near future.
Coming soon: Once this workflow is more repeatable, I'll put in results of how updating/fixing different labels influences evaluation metrics.
Repeat
With updated annotations, I let Weights & Biases Artifacts know I've made changes to the Google Storage reference files so when I rerun the train.py script, it pulls in the latest data.
And voilà!
A data engine loop completes itself!
Ideally, you want to get to a point where you can just continually:
- add or improve samples
- and the model trains
- and gets better
- and you evaluate it
- and it shows you more wrong examples (or inaccuracies)
- and you correct them
- and then the model trains again and gets better and better and better and better…
Trial and error at scale.
Or as Tesla calls it, “operation vacation”.
As in, if you set the system up correctly, you could potentially get an ever improving model, collecting data, training and self-improving whilst you sip cocktails on the beach.
Demo
Right now there's a primitive web version of Nutrify running at nutrify.app.
But the iOS version (coming soon) looks much cleaner!

Future ideas
Nutrify’s far from operation vacation stage but stay tuned… I’ve got big ideas!
- Data engine automation: Right now the data engine process is very manual, however, in future updates, I'd like to automate many of the steps, similar to the recent CiT: Curation in Training paper.
- Multiple models: I'd like a way to create multiple models (via various functions), small (deploy), medium and big (to help with labelling), right now I'm only testing one architecture.
- Object detection/segmentation: For now I'm sticking with classification, to get the overall workflow together. But later models would definitely involve object detection. I'd be looking to bootstrap labels via zero-shot object detection models such as Owl-ViT.
- Language model automation: Automate as many human tasks as possible with language models, if you can explain the task in simple plain English and it doesn’t require several steps, use a language model or several language models tied together.
- Generate synthetic images for more data: Could I boost inaccurate classes with generated images? I read a good article on this recently using 3D object scans to boost 2D image detection.
- Save and export the model to multiple formats: Right now the code is setup to export the model to PyTorch, however, since Nutrify is an iOS/web app, I'd like to automatically export trained models to Core ML (for iOS) and web formats (still deciding on the best here).
FAQ
Where can I sign up for updates?
You can enter your email for updates on the progress via Google Forms or by signing up to mrdbourke.com.
When new blog posts like this come out/the app launches, we'll send you an email.
Where can I contribute food images/food classes to include?
There's a field to enter what foods you'd like to see on Nutrify on the Google Form.
However, you can also start uploading your own food images via the Nutrify image collector app.
How did you learn to do all of this?
Lots of trial and error. I'm still figuring it out. Googling, running experiments. Copying/stealing ideas from others.
A few of my favourite full-stack machine learning resources are listed on my blog (see "level 3 deep learning").
How is Nutrify being funded?
Most of what we've done so far is free (free/open-source tools + training on local hardware).
Future expenses will be taken care of from the funds I earn from teaching machine learning and sponsorship deals from YouTube videos/blog posts (if you'd like to sponsor, please reach out).
Originally my brother went for the AI grant but we were turned down (no problems though, we'd likely apply again).
But eventually, we'd like Nutrify to become a paid application.
I can't imagine anything more fun than working on something I love and getting paid for it.
Why build Nutrify?
- Fun (most important).
- My background is in nutrition science (I graduated university with a food science and nutrition degree), I love machine learning and my brother loves iOS development, why not combine them?
- See more in our AI grant application slide deck.
What's Nutrify's end goal?
To be a Pokédex for food!
I've got an idea, how can I help?
Feel free to post on the Nutrify GitHub or contact me directly.